Large Language Models (LLMs) have shown incredible promise, yet they often grapple with challenges like generating inaccurate information (hallucinations), relying on outdated knowledge, and lacking specific domain expertise. Enter Retrieval-Augmented Generation (RAG), a groundbreaking approach that is revolutionizing the capabilities of LLMs. This guide, drawing from current research and practical implementations in the AI field, will define RAG LLM, explain precisely what is RAG in LLM contexts, detail its inner workings, highlight its benefits, explore its architecture, compare it to fine-tuning, and offer practical insights for implementation. By the end, you’ll understand how retrieval-augmented generation can significantly enhance AI performance, leading to more reliable and trustworthy AI systems.
What is Retrieval-Augmented Generation (RAG) in LLMs?

The core purpose of RAG is to significantly improve the quality and reliability of LLM-generated responses. It directly addresses the informational intent behind queries like “what is rag in llm” or “rag llm meaning,” by clarifying how this technology enhances standard rag in llm systems, making their outputs more grounded and factual.
Defining RAG: Beyond Standard LLM Capabilities
Retrieval-Augmented Generation (RAG) is a technique that enhances Large Language Models (LLMs) by integrating external, up-to-date knowledge sources before the LLM generates a response. It cleverly combines the strengths of information retrieval systems (finding relevant data) with the sophisticated generative power of LLMs. The fundamental rag llm meaning revolves around this synergy: LLMs are no longer limited to the information they were trained on. In essence, for those seeking a quick AI overview, RAG can be understood as a system that improves LLM outputs by providing them with relevant information retrieved from external sources in response to a query, ensuring answers are current and contextually appropriate. This approach is widely recognized within the AI research community as a key method for more factual AI.
The Core Problems RAG Solves for LLMs
RAG directly tackles several inherent limitations of standard LLMs, making them more suitable for real-world, critical applications:
- Hallucinations: By grounding responses in factual, verifiable data retrieved from external sources, RAG significantly reduces the chances of LLMs inventing information. This is a critical step towards building more dependable AI.
- Outdated Knowledge: LLMs are trained on static datasets, meaning their knowledge cutoff prevents them from accessing current events or information. RAG overcomes this by dynamically fetching the latest data, ensuring timeliness.
- Domain Knowledge Gaps: Standard LLMs may lack deep understanding of specialized or proprietary enterprise content. RAG enables LLMs to access and utilize this specific information, making them far more useful for niche applications and internal knowledge management.
- Lack of Transparency: While an implicit benefit, RAG can make LLM reasoning more traceable. By knowing which retrieved documents informed the response, users can gain more confidence in the output and verify the information, a crucial aspect for enterprise adoption and building user trust.
How RAG Works: A Simplified Overview of the Mechanism
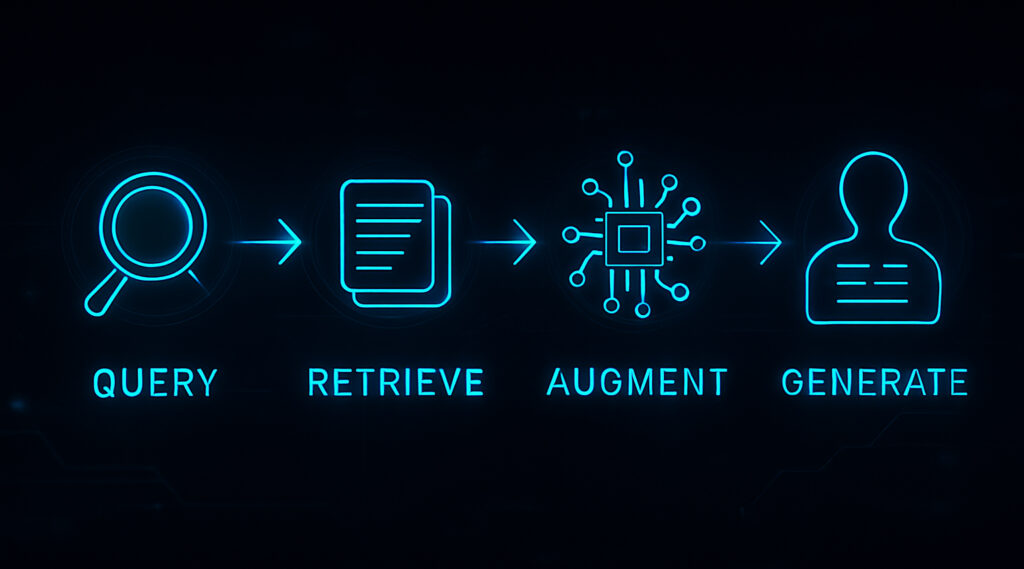
The RAG process, from a high-level technical perspective, can be broken down into a few key steps:
- User Query is Received: The process begins when a user submits a question or prompt to the system.
- Information Retrieval: An information retrieval system searches external knowledge bases (databases, enterprise document repositories, public web data) for documents or data snippets relevant to the user’s query. This often involves techniques like converting documents into vectorized documents (embeddings) and performing similarity searches. This vectorization process is critical as it allows the system to understand the semantic meaning of the text, rather than just matching keywords.
- Context Augmentation: The retrieved data snippets are then combined with the original user query to form an augmented prompt. This provides the LLM with rich, relevant context directly pertinent to the query.
- LLM Generates Response: The LLM processes this augmented prompt and generates a response that is now grounded in the provided external information, rather than relying solely on its internal, potentially outdated, parametric knowledge.
Key Benefits: Why RAG is Revolutionizing LLM Performance
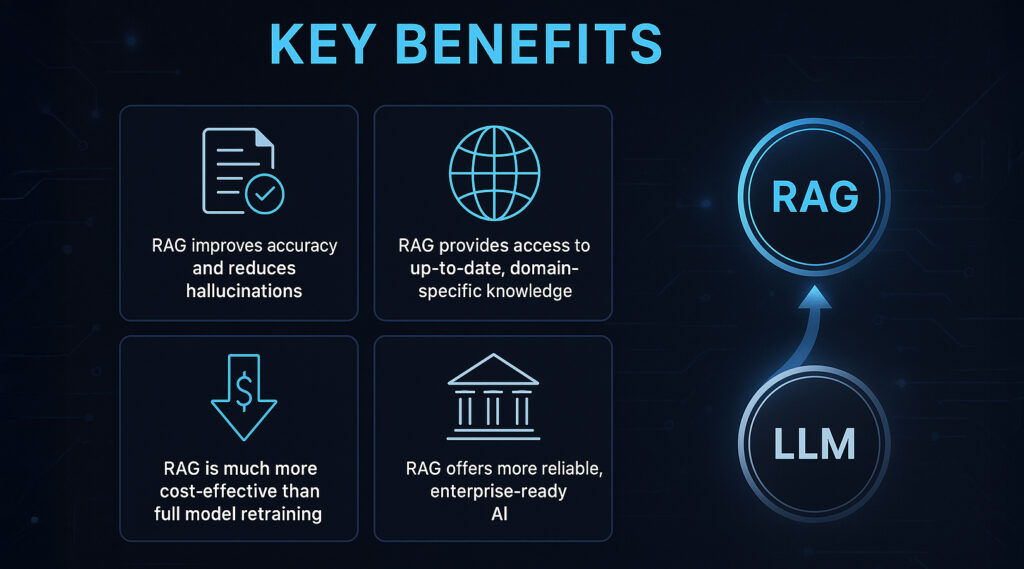
The adoption of RAG is growing rapidly due to the significant, demonstrable advantages it offers in enhancing LLM capabilities and reliability.
Drastically Improves Accuracy and Reduces Hallucinations
By providing LLMs with factual, verifiable “grounding data” retrieved in real-time, RAG ensures that responses are based on concrete information, a benefit highlighted in AI research and real-world applications. This greatly diminishes the LLM’s reliance on its parametric memory alone, which can sometimes lead to confabulation or “hallucinations.”
Access to Up-to-Date and Domain-Specific Knowledge
RAG allows LLMs to tap into information that goes far beyond their last training date. This is invaluable for applications requiring current data, such as news summarization or financial analysis. Furthermore, it’s crucial for enterprise solutions that need to leverage proprietary company knowledge, internal documentation, or rapidly changing industry-specific information.
More Cost-Effective and Efficient than Full LLM Retraining
Updating an LLM’s knowledge traditionally requires extensive and expensive retraining. With RAG, knowledge can be updated simply by adding to or modifying the external data source. This is significantly cheaper, faster, and allows for the frequent incorporation of new information without disrupting the LLM itself. This economic advantage is a significant driver for RAG adoption, especially for organizations needing to keep their AI informed with frequently changing data.
Enabling More Reliable and Trustworthy Enterprise AI Solutions
For business-critical applications, the accuracy and currency of AI-generated information are paramount. RAG builds confidence in AI outputs by making them more factual and verifiable. This, in turn, facilitates the broader adoption of Generative AI (GenAI) in enterprise environments where trust, accountability, and reliability are non-negotiable.
Understanding RAG Architecture and Components
A deeper understanding of the technical structure, often referred to as rag architecture llm or a typical rag pipeline llm, is invaluable for practitioners looking to build, evaluate, or integrate RAG systems effectively.
The Typical RAG Pipeline Explained
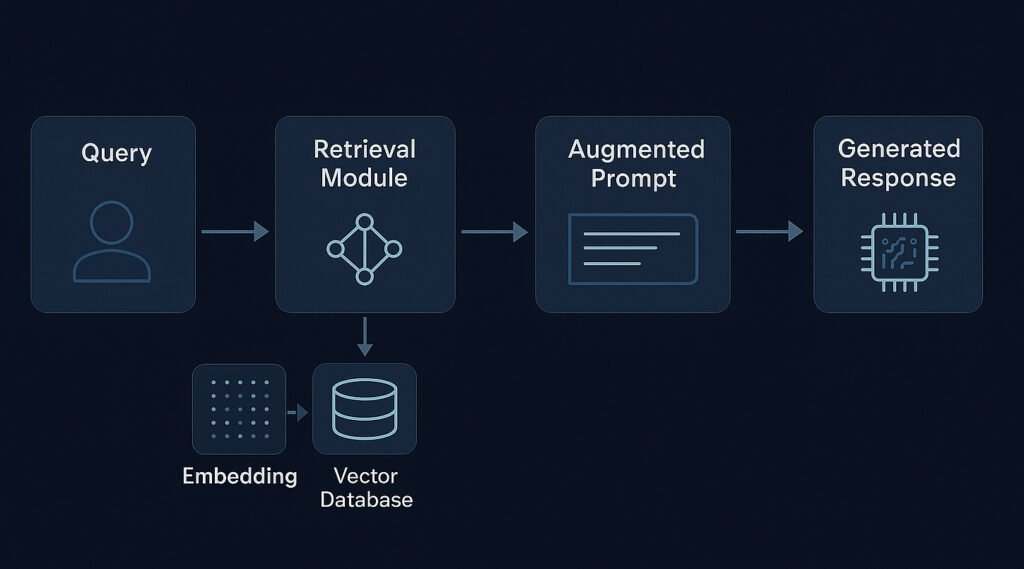
A common rag pipeline llm or llm rag architecture consists of several interconnected stages, each requiring careful design and optimization:
- Data Ingestion & Preparation: This initial phase, often considered foundational for successful RAG implementation, involves gathering knowledge from various sources (documents, databases, APIs). The data is then processed, often through “document chunking” (breaking large documents into smaller, manageable pieces) and “embedding generation” (transforming text chunks into numerical vector representations using an embedding model). These embeddings are then stored and indexed, typically in a vector database.
- Retrieval Module: When a user query comes in, it may also be converted into an embedding. The retrieval module then performs a similarity search (e.g., cosine similarity) within the vector database to find the document chunks most relevant to the query. These relevant chunks are then ranked. The effectiveness of this module is paramount, as the quality of retrieved chunks directly impacts the final output’s accuracy and relevance.
- Augmentation/Contextualization Module: The top-ranked retrieved document chunks are formatted and combined with the original user query to create an “augmented prompt.” This step is carefully designed to ensure the LLM receives the context in an optimal, digestible format that facilitates better reasoning.
Generation Module: Finally, this augmented prompt is fed to the Large Language Model (LLM). The LLM uses the provided context from the retrieved documents to generate a coherent, informed, and relevant answer to the original query.
Key Components: What You Need for a RAG System
Building a functional and robust rag system llm requires several key components, each with its own set of considerations:
- Knowledge Bases: These are the external data sources RAG draws upon. They can include internal company documents (PDFs, Word files, wikis), databases, websites, APIs, or any collection of text-based information. The quality and organization of these sources are critical.
- Embedding Models: These models, often based on transformer architectures like BERT, Sentence-BERT, or OpenAI’s Ada, are crucial for converting text (both from the knowledge base and user queries) into numerical vectors (embeddings). This allows for semantic search, where the meaning and context of the text are captured, rather than just keyword matching.
- Vector Databases: Specialized databases designed for storing, managing, and efficiently querying large volumes of vector embeddings. Examples include Pinecone, Weaviate, FAISS, and Milvus. The choice often depends on factors like data scale, query latency requirements, deployment (cloud vs. on-premise), and existing cloud infrastructure, reflecting practical considerations for deployment.
- Retrieval Models/Algorithms: These are the systems or algorithms responsible for efficiently searching the vector database and fetching the most relevant information snippets based on the user’s query. This can range from simple similarity search to more complex ranking algorithms, sometimes involving machine-learned ranking models.
- Large Language Models (LLMs): This is the generative component that takes the user’s query and the retrieved contextual information to synthesize a final answer. The choice of LLM can impact the quality, style, latency, and cost of the RAG system.
Exploring RAG Paradigms: From Naive to Advanced and Modular RAG
The field of RAG is evolving, with recent AI research, including comprehensive surveys on the topic, identifying various architectural patterns beyond a simple rag model llm:
- Naive RAG: This is the most basic form, following a straightforward “retrieve-then-read” approach. The retriever fetches relevant documents, and the LLM uses them to generate an answer. While simple to implement, it might suffer from suboptimal retrieval (e.g., irrelevant chunks) or generation (e.g., not fully utilizing the context).
- Advanced RAG: This encompasses techniques aimed at improving specific stages of the Naive RAG pipeline. For instance, pre-processing queries (e.g., query expansion, query transformation) or post-processing retrieved documents (e.g., reranking, summarization, filtering) to enhance relevance, or using iterative retrieval where the LLM can request more information if the initial context is insufficient.
- Modular RAG: This paradigm emphasizes a flexible architecture where different components (like the retriever, the generator LLM, or even memory modules) can be easily swapped, updated, or optimized independently. This offers greater adaptability and allows for tailoring the RAG system to specific needs and evolving technologies, reflecting a sophisticated engineering approach.
RAG vs. LLM Fine-Tuning: Which Approach is Right for You?

A common question for those looking to enhance LLM capabilities, and a critical decision point in designing effective AI solutions, is whether to use RAG or LLM fine-tuning. Understanding the differences, captured by searches like “llm fine tuning vs rag” or “rag vs llm,” is crucial for making the right architectural decision based on project goals and resource constraints.
Understanding LLM Fine-Tuning: Goals and Process
LLM fine-tuning is the process of taking a pre-trained Large Language Model and further training it on a smaller, domain-specific dataset. The primary goals are typically to:
- Adapt the LLM’s behavior, writing style, or tone to better match a specific brand voice or application requirement.
- Ingrain specific knowledge or teach the LLM new skills parametrically, meaning the knowledge becomes part of the model’s internal weights.
The process involves preparing a high-quality dataset, setting up a training environment, and running the fine-tuning process, which, as experienced practitioners know, can be computationally intensive and require careful hyperparameter tuning and evaluation.
RAG: Strengths and When to Use It
RAG shines due to several key strengths, making it highly effective in specific scenarios:
- Strengths: Dynamic knowledge updates (simply update the external data source without model retraining), potential for source attribution (showing users where the information came from, which is a cornerstone of building trust with AI systems), significant reduction in hallucinations for factual queries, and cost-effectiveness for incorporating rapidly changing or extensive external knowledge.
- Use Cases: Ideal for question-answering systems over dynamic document collections (e.g., technical manuals, legal documents, research papers), chatbots requiring access to current information (e.g., news, product updates), and any system where factual accuracy grounded in specific, up-to-date, and auditable sources is critical.
Fine-Tuning: Strengths and When to Use It
Fine-tuning has its own set of advantages and is preferable in other situations:
- Strengths: Effective for adapting an LLM’s style, tone, or persona; teaching the LLM new implicit skills, formats, or specialized tasks (e.g., generating code in a very particular style); and deeply embedding knowledge when external calls are not feasible or desired, or when the knowledge is relatively static but highly specialized.
- Use Cases: Adapting an LLM for a specific brand voice in marketing copy, training an LLM to perform a niche task like summarizing medical reports in a particular format, or when the required knowledge is stable and needs to be intrinsically part of the model’s behavior for low-latency responses without external calls.
Comparing RAG and Fine-Tuning: Key Differences, Pros, and Cons
Here’s a breakdown of the key distinctions to aid in decision-making:
- Knowledge Integration: RAG:* External (knowledge is retrieved from outside the LLM at query time). Fine-tuning:* Internal/Parametric (knowledge is baked into the LLM’s weights).
- Updatability: RAG:* Easy and dynamic (update the external knowledge source; changes reflected immediately). Fine-tuning:* Requires retraining or further fine-tuning, which can be resource-intensive and time-consuming.
- Cost: RAG:* Generally lower operational cost for knowledge updates. Initial setup of retrieval infrastructure is required. Inference costs include retrieval and generation. Fine-tuning:* Can be costly for frequent retraining, especially for large models. Inference costs are typically just for the LLM call.
- Hallucination Control: RAG: Better, as responses are grounded in retrieved facts. However, the quality of grounding depends directly on the relevance and accuracy of the retrieved documents.* Fine-tuning:* Can still hallucinate, though less likely on topics explicitly and thoroughly covered in the fine-tuning dataset.
Complexity: RAG: Adds complexity of retrieval infrastructure (vector databases, embedding models, retrieval logic). This often requires expertise in information retrieval and data engineering.* Fine-tuning: Requires expertise in data preparation, training processes, and hyperparameter tuning. This is typically in the domain of machine learning engineers.
Synergies: Can RAG and Fine-Tuning Be Used Together?
Yes, RAG and fine-tuning are not mutually exclusive and can be highly synergistic. A powerful hybrid approach involves:
- Fine-tuning an LLM on a domain-specific dataset to adapt its style, understand domain-specific jargon, or improve its proficiency in certain tasks relevant to that domain (e.g., better instruction following for retrieved context).
- Then, using RAG with this fine-tuned LLM to provide it with the latest, most specific, or dynamic information from that domain at query time.
This combination allows you to leverage the stylistic adaptations and specialized skills from fine-tuning while ensuring access to current and comprehensive factual knowledge through RAG, representing a best-of-both-worlds approach considered highly effective for achieving maximum performance and adaptability.
Practical Insights: Implementing and Leveraging RAG
Moving beyond theory, this section offers actionable advice, drawing from common practices and challenges observed in the field by AI practitioners, for those considering implementing RAG.
Getting Started: A Conceptual RAG LLM Example Workflow
For those looking for a “rag llm example” to understand the flow, here’s a conceptual outline, based on typical development practices, for building a basic RAG system:
- Prepare Your Knowledge Base: Gather your documents (e.g., text files, PDFs). Clean and preprocess them as needed. Consider document structure and metadata.
- Choose and Implement an Embedding Model: Select an embedding model (e.g., Sentence-BERT, OpenAI embeddings, Cohere embeddings) suitable for your content, language, and performance needs. Use it to convert your document chunks into vector embeddings.
- Set Up a Vector Store and Index Your Documents: Choose a vector database (e.g., FAISS for local experimentation, Pinecone, Weaviate, or ChromaDB for cloud-based or more robust solutions). Store your document embeddings in this database and create an index for efficient searching.
- Develop a Retrieval Function: Implement a function that takes a user query, converts it into an embedding (using the same model as in step 2), and queries the vector store to find the most similar (relevant) document chunks. Consider the number of chunks (k) to retrieve.
- Integrate with an LLM API: Pass the retrieved document chunks (as context) along with the original user query to an LLM (e.g., via an API like OpenAI’s GPT models, Anthropic’s Claude, or a self-hosted model like Llama). Craft your prompt carefully to instruct the LLM to use the provided context to answer the question accurately and concisely. Effective prompt engineering is a key skill in maximizing RAG performance and often requires iteration.This is a simplified overview; a full tutorial, often sought by developers, would delve deeper into each step, including code snippets, debugging tips, and performance optimization strategies.
Considerations for Choosing the “Best” LLM for RAG
There isn’t a single “best llm for rag” as the optimal choice generally depends heavily on specific project requirements, budget, performance needs, and existing infrastructure. However, here are key factors to consider:
- Context Window Size: LLMs have limits on the amount of text they can process at once (context window). For RAG, a larger context window is often better as it allows more retrieved information to be passed to the LLM, potentially improving answer quality and reducing the need for aggressive context truncation.
- Instruction-Following Capabilities: The LLM needs to be good at following instructions to effectively use the provided context and answer the specific query, rather than ignoring the context or going off-topic. Models specifically benchmarked for instruction-following (e.g., FLAN-T5, newer GPT versions, models fine-tuned on instruction datasets) often perform well here.
- Cost Per Token/Call: LLM usage is often priced per token (input and output). Consider the cost implications, especially for high-volume applications. Factor in both the cost of processing the prompt (including retrieved context) and generating the response.
- Specific Strengths: Some LLMs might be better at reasoning, others at summarization, or creative generation. Choose one whose strengths align with your RAG application’s primary task (e.g., factual Q&A, summarization of retrieved documents).
- Ease of Integration: Consider how easily the LLM can be integrated into your RAG pipeline, including API availability, quality of documentation, client libraries, and active community support, which can significantly reduce development friction and time-to-market.
- Latency Requirements: Different LLMs have different inference speeds. If low latency is critical, this will be a major factor in model selection.
What a “RAG LLM Tutorial” Would Cover
Users searching for a “rag llm tutorial” or “llm rag tutorial” are looking for hands-on, step-by-step guidance. A comprehensive, high-quality tutorial designed for practitioners would typically cover:
- Setting up the Environment: Installing necessary libraries (e.g., LangChain, LlamaIndex, sentence-transformers, vector database clients like pinecone-client or weaviate-client), and configuring API keys for LLMs and other services.
- Loading and Chunking Documents: Demonstrating how to load various document types (TXT, PDF, HTML, Markdown) and strategically split them into smaller, semantically meaningful chunks, including discussing common strategies and considerations for chunk size and overlap.
- Generating Embeddings and Storing in a Vector DB: Walking through the process of using a chosen embedding model and indexing the resulting vectors in a selected vector database (e.g., FAISS for local use, or a managed service like Pinecone or Chroma).
- Implementing a Retrieval Function: Writing code to take a query, embed it, and retrieve relevant chunks from the vector database, potentially including techniques for tuning the number of retrieved documents (top-k).
- Crafting Prompts for the LLM: Showing how to construct effective prompts that clearly instruct the LLM to use the retrieved context to answer the query, avoid making up information, and cite sources if applicable. This is often an iterative process of refinement based on observed outputs and desired behavior.
- Running Queries and Evaluating Results: Demonstrating how to run the end-to-end RAG system and offering practical strategies and key metrics for evaluating the quality of the generated responses (e.g., relevance, factual consistency, faithfulness to sources, and context utilization). Frameworks like RAGAs might be introduced here.
Potential Challenges and Considerations in RAG Implementation
While RAG offers significant benefits, it’s important to approach implementation with an awareness of potential challenges, which practitioners frequently encounter and must address for robust solutions:
- Retrieval Quality: The “garbage in, garbage out” principle applies with rigor. If the retrieval step fetches irrelevant or low-quality information, the LLM’s response will likely suffer, regardless of the LLM’s capabilities. Optimizing retrieval, often through techniques like query expansion, reranking, hybrid search (combining keyword and semantic search), or fine-tuning embedding models, is crucial.
- Chunking Strategy: The size, overlap, and content of document chunks can significantly impact retrieval performance and the context provided to the LLM. Finding the optimal strategy often requires careful experimentation and evaluation against your specific dataset and use case.
- Context Length Limitations of LLMs: Even with large context windows, there’s a limit to how much information can be passed. Strategies for summarizing retrieved text, selecting the most critical pieces, or re-ranking chunks to fit within the context window might be necessary, especially with very large retrieved contexts.
- Latency: The retrieval step adds an extra processing stage, which can introduce latency compared to querying an LLM directly. Optimizing retrieval speed, perhaps through efficient indexing, caching strategies, or faster embedding models/vector databases, is important for real-time applications.
- Cost: There are costs associated with embedding generation (if using paid APIs or GPU resources), vector database hosting/usage, and LLM API calls. These need to be carefully modeled and factored into the overall system design and operational budget.
- Evaluation Complexity: Measuring the performance of a RAG system can be complex. Metrics need to assess not just the fluency of the generated text but also its factual accuracy, relevance based on the retrieved documents, and faithfulness (avoiding contradiction with sources). Frameworks like RAGAS or custom evaluation pipelines aim to standardize and automate parts of this evaluation process.
The Future of RAG and LLMs

Retrieval-Augmented Generation is not a static concept; it’s an actively evolving field, with leading researchers, academic institutions, and industry labs continually pushing the boundaries of what’s possible.
Evolving RAG Techniques and Innovations
Ongoing research, often published on platforms like Arxiv or presented at major AI conferences (e.g., NeurIPS, ICML, ACL), is pushing the boundaries of RAG capabilities. We are seeing innovations in:
- Hybrid Retrieval Methods: Combining dense vector search (semantic) with traditional keyword-based search (lexical) for more robust and nuanced retrieval, capturing both semantic similarity and exact matches.
- Adaptive Retrieval (Self-Correcting RAG): Systems where the LLM or an intermediary agent can assess the initial retrieved documents and decide if more, or different, information is needed, potentially re-querying the knowledge base or reformulating the query. This mirrors a more human-like research process.
- Conversational RAG: Extending RAG to maintain context and retrieve information effectively over multiple turns in a dialogue, understanding follow-up questions and coreferences.
- Multi-Hop Retrieval: Enabling the system to traverse multiple documents or data points to synthesize an answer that requires connecting disparate pieces of information, performing more complex reasoning.
- Integration with LLM agents and more complex reasoning workflows: Allowing RAG to be a core component in sophisticated problem-solving systems where the LLM can decide when and how to use the retrieval tool.
RAG’s Expanding Role in Enterprise and Specialized AI
RAG is poised to play an increasingly critical role in making Generative AI more trustworthy, applicable, and scalable for businesses. Its ability to ground LLMs in factual, up-to-date, and domain-specific knowledge is essential for enterprise use cases where ROI, accuracy, and risk mitigation are key drivers. We anticipate seeing RAG used more extensively for:
- Customizing general-purpose LLMs for highly specific knowledge domains (e.g., finance, legal, healthcare, engineering) without the need for costly and frequent full model retraining.
- Powering next-generation enterprise search and knowledge discovery platforms, offering natural language answers instead of just lists of documents.
- Enhancing AI assistants and copilots with reliable, context-aware information retrieval capabilities, making them truly helpful.
- Ensuring compliance and auditability in regulated industries by providing traceable sources for AI-generated content.
Conclusion
Retrieval-Augmented Generation (RAG) stands out as a pivotal technology for unlocking the full potential of Large Language Models in practical, real-world scenarios. By enabling LLMs to access and utilize external, up-to-date, and domain-specific knowledge, RAG makes them significantly more accurate, current, reliable, and ultimately, more useful.
The key takeaway, supported by growing adoption and extensive research, is that RAG LLM systems bridge the critical gap between the general, pre-trained knowledge of LLMs and the specific, timely information crucial for most real-world applications. This empowers developers and organizations to build more intelligent, trustworthy, and truly useful AI-powered solutions, moving beyond proof-of-concept to production-ready applications that deliver tangible value.
Explore how implementing a RAG strategy can enhance your AI-powered solutions or start building more knowledgeable and trustworthy AI applications with RAG today. The journey towards more factual and context-aware AI is significantly accelerated by this powerful approach.
Frequently Asked Questions (FAQ) about RAG LLMs
Think of it like giving an LLM an open-book exam. Instead of relying only on what it “memorized” during its training (which can be vast but not always current or specific enough), RAG allows the LLM to quickly “look up” relevant information from a specific, up-to-date “book” (your external knowledge base) before answering your question. This makes its answers much more accurate, current, and relevant to your specific needs.
RAG improves LLM accuracy by providing factual, relevant information (retrieved from your trusted sources) as context for each query. This “grounds” the LLM’s response in verifiable data, significantly reducing its tendency to guess, make things up, or “hallucinate” answers. This grounding mechanism is well-documented for its effectiveness in mitigating common LLM errors and increasing user trust.
Neither is universally “better”; they serve different purposes and, as discussed in detail earlier, can even be highly complementary. RAG excels at incorporating dynamic, factual, and extensive external knowledge that changes frequently, and for providing source attribution. Fine-tuning is more suited for adapting an LLM’s style, tone, or teaching it specific tasks or implicit knowledge that doesn’t rely on external lookup. For many scenarios, using RAG with a fine-tuned model offers the best of both worlds, combining tailored behavior with access to fresh, specific data.
Common use cases for RAG LLMs span many industries and applications:
- Customer support chatbots that access current product manuals, troubleshooting guides, and FAQs to provide accurate assistance.
- Internal knowledge base Q&A systems for employees to quickly find company policies, technical documentation, or project information.
- Content generation tools that need to cite recent data, specific sources, or adhere to particular factual constraints.
- Financial analysis tools that incorporate up-to-the-minute market data, company reports, and regulatory filings.
- Healthcare applications providing information to medical professionals based on the latest medical research and clinical guidelines (while always ensuring human oversight for critical decisions).These examples illustrate the versatility of RAG in scenarios demanding accuracy and access to specific, current data.
RAG can, in principle, utilize virtually any text-based data source that can be processed and indexed. This includes a diverse range of materials:
- Internal company documents: PDFs, Word documents, PowerPoint presentations, Confluence pages, SharePoint sites, Google Docs.
- Websites and web content: Articles, blog posts, news sites (with appropriate scraping and parsing).
- Databases (SQL or NoSQL) containing textual information or metadata that can be converted to text.
- Product catalogs, technical specifications, and FAQs.
- Scientific papers, research articles, and academic journals.
- Customer service transcripts, support tickets, and internal knowledge articles.The key is to ensure the data is clean, relevant, and well-structured for effective retrieval.