Large Language Models (LLM – büyük dil modelleri) olağanüstü bir potansiyele sahip olsa da, yanlış bilgi üretme (halüsinasyon), güncelliğini yitirmiş bilgilere dayanma ve belirli alanlarda uzmanlık eksikliği gibi önemli zorluklarla karşı karşıyadır. Tam da bu noktada devreye Retrieval-Augmented Generation (RAG – almayla artırılmış üretim) girer. RAG, LLM’lerin yeteneklerini dönüştüren devrim niteliğinde bir yaklaşımdır.
Bu rehber, güncel araştırmalara ve yapay zekâ alanındaki pratik uygulamalara dayanarak RAG LLM kavramını açıklayacak; “LLM içinde RAG nedir?” gibi sorulara net yanıtlar sunacak, nasıl çalıştığını detaylandıracak, avantajlarını ortaya koyacak, mimarisini inceleyecek, fine-tuning (ince ayar) yöntemiyle karşılaştıracak ve uygulama sürecine dair pratik bilgiler paylaşacaktır. İçeriğin sonunda, retrieval-augmented generation yönteminin yapay zekâ performansını nasıl belirgin biçimde artırabileceğini ve daha güvenilir sistemlerin inşasında nasıl bir rol oynadığını göreceksiniz.
LLM’lerde Retrieval-Augmented Generation (RAG) Nedir?

RAG, LLM’lerin yanıt üretmeden önce harici bilgi kaynaklarına erişmesini sağlayan bir yaklaşımdır. Bilgi alma sistemlerinin (yani ilgili verileri bulma yeteneğinin) gücünü, LLM’lerin gelişmiş metin üretim kabiliyetiyle birleştirir.
RAG LLM kavramının temelinde bu sinerji yer alır: Artık LLM’ler yalnızca eğitildikleri veriyle sınırlı değildir. RAG sayesinde, dış kaynaklardan sorguya özel bilgi çekebilir, böylece bağlama uygun, güncel ve güvenilir yanıtlar oluşturabilir. Yapay zekâ araştırmaları açısından bu yaklaşım, daha gerçekçi ve doğruluğu yüksek üretim sağlamak için öne çıkan yöntemlerden biridir.
RAG’in LLM’lerde Çözdüğü Temel Sorunlar
RAG, LLM’lerin bazı temel kısıtlarını aşarak yapay zekâyı gerçek dünya uygulamalarına daha uygun hâle getirir:
- Halüsinasyonlar (Uydurma Bilgi): LLM’ler bazen gerçekte olmayan ama ikna edici görünen bilgiler üretir. RAG, dış kaynaklardan alınan doğrulanabilir verilerle bu riski önemli ölçüde azaltır.
- Güncellik Sorunu: LLM’ler, sabit veri kümeleriyle eğitildiğinden güncel bilgilere erişemez. RAG, sorgu anında güncel veri çekerek bu sınırlamayı ortadan kaldırır.
- Alan Uzmanlığı Eksikliği: Standart LLM’ler özel alanlara ait içeriklere hâkim değildir. RAG, sektöre özgü ya da uzmanlık gerektiren bilgileri modele sunarak, bu eksikliği giderir.
Şeffaflık Eksikliği: RAG ile üretilen yanıtların hangi kaynaklara dayandığı görülebilir. Bu da hem kurumsal kullanımlar hem de kullanıcı güveni açısından büyük avantaj sağlar.
RAG Nasıl Çalışır? Basit Bir Mekanizma Özeti
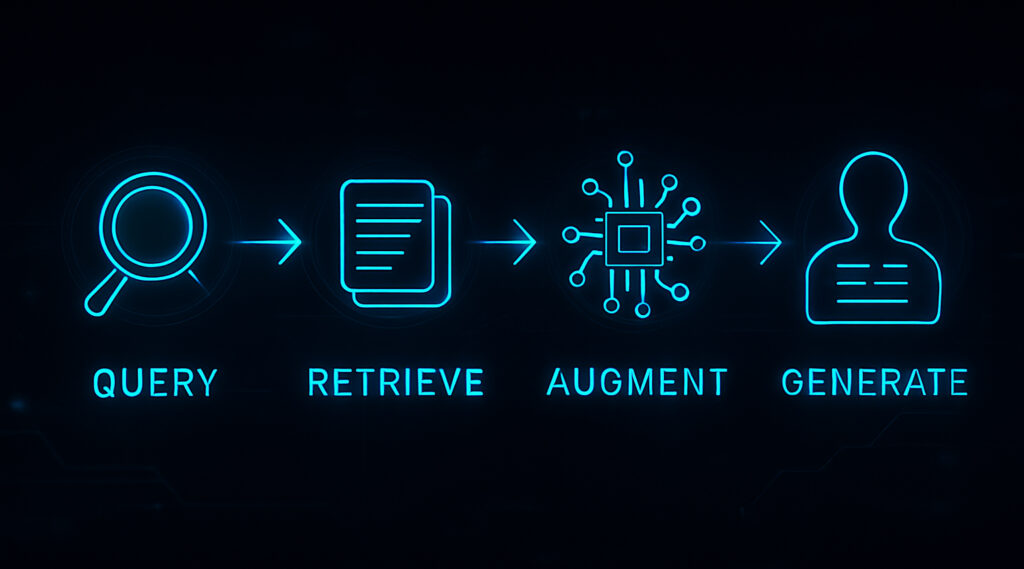
RAG’in çalışma süreci teknik olarak birkaç temel adımdan oluşur:
- Kullanıcı Sorgusunun Alınması: Süreç, kullanıcının bir soru ya da istem göndermesiyle başlar.
- Bilgi Getirme (Retrieval): Sistem, dış bilgi kaynaklarında (veritabanları, doküman havuzları, halka açık web verileri) sorguyla ilgili belge ya da veri parçalarını arar. Bu işlem genellikle belgelerin vektör temsillere (embedding) dönüştürülmesi ve anlamsal benzerlik aramalarıyla yapılır.
- Bağlam Zenginleştirme: Elde edilen veriler, kullanıcı sorgusuyla birleştirilerek LLM’ye gönderilecek gelişmiş bir istem oluşturulur. Bu, modele doğrudan bağlam kazandırır.
Yanıt Üretimi: LLM, bu artırılmış istemi işler ve artık sadece kendi iç bilgisini değil, dışarıdan alınmış güncel ve alakalı verileri de kullanarak yanıt üretir.
Temel Avantajlar: RAG Neden LLM Performansında Devrim Yaratıyor?
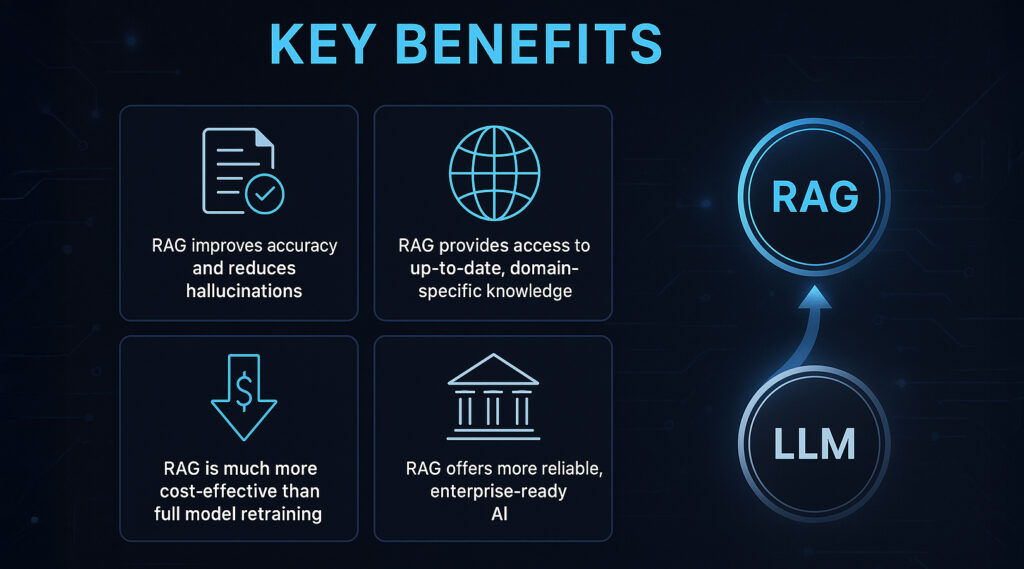
Retrieval-Augmented Generation (RAG – almayla artırılmış üretim) yaklaşımı, Large Language Model (LLM – büyük dil modeli) sistemlerinin performansını ve güvenilirliğini artırma konusundaki kanıtlanmış başarıları sayesinde hızla yaygınlaşmaktadır.
RAG, Doğruluğu Belirgin Şekilde Artırır ve Halüsinasyonları Azaltır
RAG, LLM’lere gerçek zamanlı olarak doğrulanabilir “dayanak verisi” (grounding data) sağlayarak yanıtların somut ve güvenilir bilgilere dayanmasını mümkün kılar. Bu, yalnızca parametre belleği (parametric memory) ile çalışan klasik modellerin sıklıkla karşılaştığı halüsinasyon (uydurma bilgi) üretimi sorununu önemli ölçüde azaltır. Bu fayda, akademik yayınlarda ve kurumsal uygulamalarda defalarca ortaya konmuştur.
RAG Güncel ve Alan-Spesifik Bilgiye Erişim Sağlar
RAG kullanan sistemler, yalnızca modelin eğitim tarihine kadar olan bilgilerle sınırlı kalmaz. Haber özeti oluşturma, finansal analiz ya da sektöre özgü içerik üretimi gibi güncel veri gerektiren uygulamalarda bu özellik büyük avantaj sağlar. Ayrıca kurum içi özel dokümanlara, sürekli güncellenen teknik bilgilere veya uzmanlık gerektiren içeriklere erişim imkânı sunarak, RAG’i kurumsal çözümler için vazgeçilmez kılar.
RAG, Modeli Baştan Eğitmeden Bilgiyi Güncellemenin Ekonomik Yoludur
Bir LLM’nin bilgi altyapısını güncellemenin geleneksel yolu, yeniden eğitimdir. Ancak bu süreç oldukça maliyetli, zaman alıcı ve teknik olarak karmaşıktır. RAG yaklaşımı ise yalnızca harici bilgi kaynağının güncellenmesiyle yeni verileri sisteme entegre etmeyi mümkün kılar. Bu yöntem hem çok daha düşük maliyetlidir hem de modeli yeniden eğitmeden güncel bilgiyi devreye almayı sağlar. Bu yönüyle, özellikle sık veri güncellemesi gereken sektörlerde RAG’in benimsenmesi hızla artmaktadır.
RAG, Daha Güvenilir ve Kurumsal Düzeyde Uygulanabilir Yapay Zekâ Sunar
Üretken yapay zekâ (GenAI – generative AI) sistemlerinin kurumsal alanda kullanılabilmesi için üretilen bilgilerin doğruluğu, güncelliği ve kaynak güvenilirliği tartışmasız olmalıdır. RAG, bu gereksinimleri karşılayarak yapay zekâ sistemlerinin güvenilirliğini ve benimsenebilirliğini artırır. Böylece kurumlar, hesap verebilirlik ve doğruluk kriterlerine uygun, denetlenebilir yapay zekâ uygulamaları geliştirme yolunda önemli bir adım atmış olur.
RAG Mimarisi ve Bileşenlerini Anlamak
Retrieval-Augmented Generation (RAG) sistemlerini kurmak, değerlendirmek veya mevcut yapılarla entegre etmek isteyen profesyoneller için teknik yapıyı derinlemesine anlamak kritik önemdedir. Bu yapı, literatürde sıkça “RAG architecture LLM” veya “typical RAG pipeline LLM” terimleriyle ifade edilir.
Tipik Bir RAG Süreci Nasıl İşler?
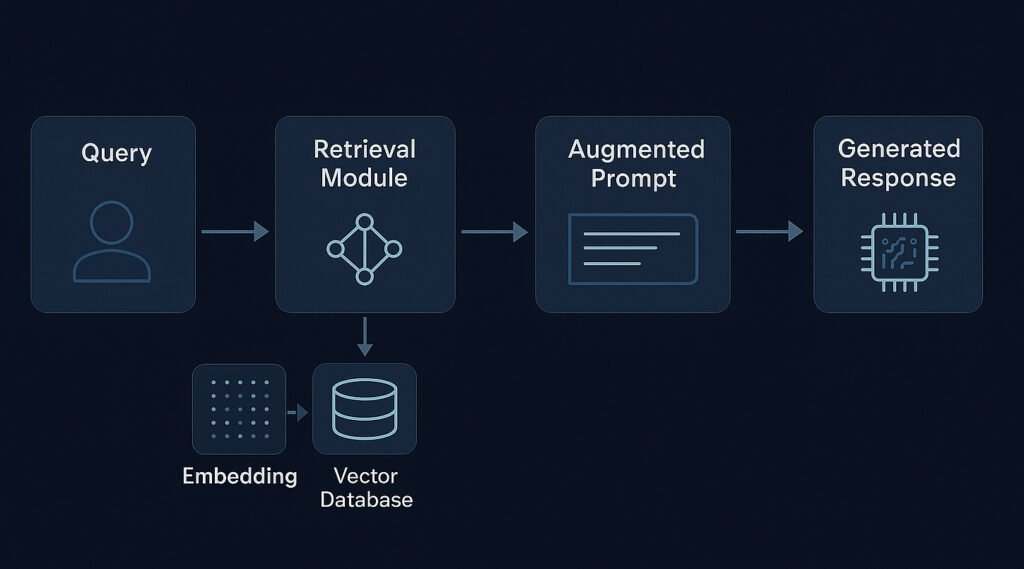
Standart bir RAG mimarisi, LLM senaryosunda birbiriyle entegre çalışan birkaç temel aşamadan oluşur. Bu aşamaların her biri dikkatle tasarlanmalı ve kullanım senaryosuna göre optimize edilmelidir:
1. Veri Toplama ve Hazırlama
Başarılı bir RAG sisteminin temeli, doğru ve yapılandırılmış bilgi kaynaklarına dayanır. Bu aşamada farklı kaynaklardan (dokümanlar, veritabanları, API’ler) içerikler toplanır. Toplanan belgeler genellikle küçük parçalara bölünür (chunking) ve bu metin parçaları sayısal vektör temsillere dönüştürülür (embedding). Elde edilen embedding’ler, arama yapılabilmesi için bir vektör veritabanına kaydedilir ve indekslenir.
2. Retrieval Modülü
Kullanıcıdan gelen sorgu da aynı embedding modeliyle vektöre dönüştürülür. Retrieval modülü, bu vektörü kullanarak vektör veritabanında benzerlik araması (örneğin cosine similarity) gerçekleştirir. Sorguyla en alakalı belge parçaları seçilir ve önem sırasına göre sıralanır. Bu modülün başarımı, RAG sisteminin genel doğruluğunu ve güvenilirliğini doğrudan etkiler.
- Bağlam Zenginleştirme
Seçilen en uygun belge parçaları, orijinal kullanıcı sorgusuyla birlikte yapılandırılarak “augmented prompt” (zenginleştirilmiş istem) oluşturulur. Bu istem, LLM’nin verilen bilgiyi en iyi şekilde değerlendirmesini sağlayacak biçimde hazırlanır. Formatlama ve bağlamın sunuluş şekli bu aşamada kritik rol oynar.
4. Yanıt Üretimi
Son olarak bu zenginleştirilmiş prompt, LLM’ye gönderilir. LLM, yalnızca kendi eğitim verisine değil, dışarıdan getirilen bu güncel ve alakalı bağlama da dayanarak tutarlı, açıklayıcı ve sorguya uygun bir yanıt üretir.
RAG Sisteminde Yer Alan Temel Bileşenler
Etkili bir RAG sistemi oluşturmak için aşağıdaki temel bileşenlerin her biri özenle seçilmeli ve sistemin genel ihtiyaçlarına göre yapılandırılmalıdır:
Bilgi Tabanları: RAG’in temelini oluşturan dış veri kaynaklarıdır. Şirket içi belgeler (PDF, Word, Wiki sayfaları), veri tabanları, web siteleri ve API’ler gibi her türlü metin tabanlı içerik bilgi tabanı olarak kullanılabilir. Bu kaynakların kalitesi, doğruluğu ve yapısal bütünlüğü, sistemin başarımını doğrudan etkiler.
Embedding Modelleri: BERT, Sentence-BERT veya OpenAI Ada gibi transformer tabanlı modeller, metni sayısal vektörlere dönüştürür. Bu dönüşüm, sistemin anlam bazlı arama (semantic search) yapabilmesini sağlar. Seçilen embedding modeli, hem doğruluk hem de hız açısından kritik bir bileşendir.
Vektör Veritabanları: Oluşturulan embedding’lerin depolandığı ve sorgulandığı özel veri tabanlarıdır. Yaygın örnekler arasında Pinecone, Weaviate, FAISS ve Milvus yer alır. Hangi vektör veritabanının kullanılacağı; veri miktarı, sorgu gecikmesi, dağıtım yöntemi (bulut ya da yerel) ve sistem altyapısı gibi etkenlere göre belirlenmelidir.
Retrieval Algoritmaları: Vektör veritabanından en alakalı bilgi parçalarını hızlı ve etkili şekilde getirmek için kullanılır. Bu algoritmalar, basit benzerlik eşleştirmelerinden (örneğin cosine similarity) daha gelişmiş yeniden sıralama (reranking) ve filtreleme mekanizmalarına kadar farklı düzeylerde olabilir.
Large Language Models (LLMs): Son adımda, kullanıcı sorgusu ve getirilen bağlamı kullanarak nihai cevabı oluşturan dil modelleridir. Seçilen LLM, yanıtın doğruluğu, üretim süresi ve sistem maliyeti üzerinde doğrudan belirleyicidir.
Farklı RAG Yaklaşımlarına Genel Bakış: Basitten Modüler Yapılara
RAG mimarisi, sürekli gelişen bir alan olarak farklı uygulama düzeylerini ve mühendislik yaklaşımlarını içermektedir. Güncel araştırmalar, yalnızca temel yapılara değil, çok daha esnek ve güçlü sistem mimarilerine işaret eden çeşitli RAG paradigmalarını ortaya koymaktadır:
Naif RAG: En basit ve doğrudan uygulanan modeldir. “Önce getir, sonra oku” (retrieve-then-read) mantığıyla çalışır. Uygulaması kolaydır; ancak veri getirme veya yanıt üretme adımları optimal düzeyde olmayabilir. İlgili belgelerin kalitesi düşükse, LLM’nin çıktısı da zayıf olabilir.
Gelişmiş RAG: Bu yaklaşım, daha karmaşık sorgu ön işleme (örneğin sorgu genişletme ya da dönüştürme) ve belge son işleme (yeniden sıralama, özet çıkarma, içerik filtreleme) yöntemlerini içerir. Ayrıca, LLM’nin ilk getirilen içerikleri yeterli bulmaması durumunda yeni bilgiler talep etmesine olanak tanıyan iteratif retrieval (yinelemeli getirme) gibi teknikler de bu kategoriye girer.
Modüler RAG: En esnek mimariyi sunan yaklaşımdır. Sistem, farklı bileşenlerin (retriever, LLM, bellek modülleri vb.) bağımsız olarak güncellenip değiştirilebildiği bir yapı üzerine kuruludur. Bu, RAG sisteminin belirli kullanım senaryolarına göre özelleştirilmesini ve yeni teknolojilerle kolay entegrasyonunu mümkün kılar. Özellikle büyük ölçekli ya da uzun ömürlü yapay zekâ projeleri için idealdir.
RAG vs. LLM Fine-Tuning: Hangi Yaklaşım Size Uygun?

LLM (Large Language Model – büyük dil modeli) yeteneklerini geliştirmek isteyenler için en kritik kararlardan biri şudur: RAG mi kullanılmalı, yoksa fine-tuning mi yapılmalı? “LLM fine-tuning vs RAG” ya da “RAG vs LLM” gibi aramalarda da görüldüğü gibi bu karar, proje hedeflerinize ve teknik kaynaklarınıza göre en uygun yapının seçilmesini gerektirir.
LLM Fine-Tuning Nedir? Amaçları ve Süreci
LLM fine-tuning, önceden eğitilmiş bir modelin daha küçük ve alanına özgü bir veri setiyle tekrar eğitilmesidir. Temel hedefler:
- Modelin yazım tarzını, ses tonunu veya davranışını belirli bir kullanım senaryosuna ya da marka diline uyarlamak
- Özel bilgi ve becerileri modele içsel olarak öğretmek (bilginin modelin parametrelerine gömülmesi)
Bu süreç; kaliteli veri seti, uygun eğitim altyapısı, dikkatli hiperparametre ayarları ve iyi planlanmış değerlendirme aşamaları gerektirir. Hesaplama açısından yoğun ve maliyetlidir.
RAG’in Güçlü Yönleri ve Hangi Durumlarda Tercih Edilmeli?
Avantajları:
- Modeli yeniden eğitmeye gerek kalmadan dinamik bilgi güncellemesi yapılabilir
- Kaynak gösterme yeteneği sayesinde şeffaflık sağlanır
- Halüsinasyon (uydurma bilgi üretme) riski önemli ölçüde azaltılır
- Geniş veya sürekli güncellenen bilgi gerektiren sistemlerde düşük maliyetli çözüm sunar
Uygulama Alanları:
- Sürekli güncellenen belgeler üzerinde çalışan soru-cevap sistemleri (örn. teknik dökümanlar, yasal belgeler, akademik makaleler)
- Güncel bilgiye ihtiyaç duyan sohbet botları (örn. haber, ürün bilgisi, finansal içerik)
- Bilgi doğruluğunun kritik olduğu kurumsal çözümler (örn. denetim, mevzuat, iç kontrol sistemleri)
Fine-Tuning’in Güçlü Yönleri ve Hangi Durumlarda Tercih Edilmeli?
Avantajları:
- Modelin yazım tarzı, tonu veya kişiliği özelleştirilebilir
- Yeni beceri veya özel formatlar öğretilebilir (örn. belirli bir kod stilinde programlama)
- Harici veri çağrısının istenmediği, sabit bilgi gerektiren durumlarda uygundur
Uygulama Alanları:
- Marka diline uygun metin üretimi (örn. pazarlama, reklam)
- Tıbbi raporlar gibi uzmanlık gerektiren içeriklerin belirli formatta özetlenmesi
- Harici veri kaynağına erişim olmadan, düşük gecikmeli yanıt üretimi gereken senaryolar
RAG ve Fine-Tuning Karşılaştırması
| Kriter | RAG | Fine-Tuning |
|---|---|---|
| Bilgi Kaynağı | Harici (sorgu anında çekilir) | Dahili / Parametrik (model içine gömülür) |
| Güncellenebilirlik | Kolay ve anlık (veri kaynağını değiştirerek) | Zor ve maliyetli (yeniden eğitim gerekir) |
| Maliyet | Düşük işletme maliyeti, ancak altyapı kurulur | Büyük modellerde pahalı, sık güncellemelerde maliyet artar |
| Halüsinasyon Riski | Düşük (veri destekli yanıt) | Vardır (veri dışına çıktığında) |
| Teknik Karmaşıklık | Altyapı, embedding ve retrieval bilgisi gerekir | Eğitim süreci ve veri hazırlığı gerekir |
RAG Nasıl Kurulur ve Kullanılır?
Teoriden pratiğe geçmek isteyenler için bu bölüm, sahadaki deneyimlerden yola çıkarak uygulanabilir adımlar sunar.
RAG LLM İçin Kavramsal Bir Örnek İş Akışı
“RAG LLM örneği” arayanlar için temel bir sistem şu adımlarla kurulur:
- Bilgi Tabanını Hazırla:
- PDF, TXT gibi belgeleri topla, temizle ve yapılandır.
- Belge yapısı ve varsa meta veriler dikkate alınmalıdır.
- PDF, TXT gibi belgeleri topla, temizle ve yapılandır.
- Embedding Modeli Seç ve Uygula:
- İçeriğe ve dile uygun bir embedding modeli seç (Sentence-BERT, OpenAI, Cohere vb.).
- Belgeleri anlamlı parçalara böl, her parçayı vektöre dönüştür.
- İçeriğe ve dile uygun bir embedding modeli seç (Sentence-BERT, OpenAI, Cohere vb.).
- Vektör Veritabanı Kur ve Belgeleri İndeksle:
- FAISS, Pinecone, Weaviate veya ChromaDB gibi bir sistem seç.
- Embedding’leri yükle, indeks oluştur.
- FAISS, Pinecone, Weaviate veya ChromaDB gibi bir sistem seç.
- Veri Getirme Fonksiyonu Geliştir:
- Sorguyu embedding’e çevir.
- Vektör veritabanından benzer parçaları getir (top-k ayarına dikkat).
- Sorguyu embedding’e çevir.
- LLM API Entegrasyonu Yap:
- Getirilen içerik + orijinal sorgu ile etkili bir prompt hazırla.
- GPT, Claude veya Llama gibi bir LLM’den yanıt al.
- Başarılı bir sistem için prompt engineering sürecine önem ver.
- Getirilen içerik + orijinal sorgu ile etkili bir prompt hazırla.
RAG İçin “En İyi” LLM Nasıl Seçilir?
“Best LLM for RAG” sorusunun yanıtı projeye göre değişir. Değerlendirilmesi gereken başlıca faktörler:
- Bağlam Penceresi (Context Window):
Büyük context window, daha fazla bilgi iletimi demektir. - Talimat Takibi Yeteneği:
Instruction-tuned modeller (GPT-4, FLAN-T5) tercih edilir. - Maliyet:
Token bazlı ücretlendirme, yüksek hacimli kullanımda etkili olur. - Uzmanlık Alanı:
Özetleme, muhakeme veya yaratıcı üretim gibi alanlara göre model seçilmelidir. - Entegrasyon Kolaylığı:
API, dokümantasyon ve topluluk desteği geliştirme süresini etkiler. - Gecikme Süresi:
Gerçek zamanlı uygulamalarda hız kritik rol oynar.
“RAG LLM Tutorial” İçeriğinde Neler Olmalı?
Kaliteli bir pratik eğitim kılavuzu şunları içermelidir:
- Ortam Kurulumu:
LangChain, LlamaIndex, sentence-transformers gibi kütüphaneler kurulmalı.
API anahtarları tanımlanmalı. - Belge Yükleme ve Parçalama:
TXT, PDF, HTML, Markdown dosyaları okunur, anlamlı bloklara bölünür.
Chunk boyutu ve overlap stratejileri açıklanmalı. - Embedding Üretimi ve İndeksleme:
Embedding modeli seçilir, belgeler vektöre dönüştürülür ve FAISS, Pinecone gibi veritabanına kaydedilir. - Retrieval Fonksiyonu Geliştirme:
Sorgular embedding’e çevrilir. Top-k yapılandırması örneklerle gösterilir. - LLM için Etkili Prompt Yazımı:
Doğru bağlam kullanımı için istemler yazılır.
Deneme-yanılma ile geliştirme örneklenir.
Sorgu ve Yanıt Değerlendirmesi:
Üretilen yanıtlar; alaka, doğruluk, bağlam uyumu açısından değerlendirilir.
RAGAs gibi metrik tabanlı framework’ler tanıtılabilir.
RAG Uygulamalarında Karşılaşılabilecek Zorluklar ve Dikkat Edilmesi Gereken Noktalar
RAG (retrieval-augmented generation – almayla artırılmış üretim) yaklaşımı önemli avantajlar sunsa da, uygulama sürecine geçmeden önce bazı zorlukların farkında olmak ve bunlara karşı önlem almak gerekir. Aşağıda, sahada sıkça karşılaşılan teknik ve operasyonel engeller yer almaktadır:
- Getirilen Bilginin Kalitesi
“Çöp girerse çöp çıkar” prensibi RAG için fazlasıyla geçerlidir. Eğer getirme (retrieval) adımı, alakasız veya düşük kaliteli veri dönerse, LLM (large language model – büyük dil modeli) ne kadar güçlü olursa olsun yanıtın kalitesi düşer. Bu nedenle sorgu genişletme, yeniden sıralama (reranking), hibrit arama (anahtar kelime + anlamsal arama) gibi yöntemlerle getirme kalitesini optimize etmek kritik önemdedir. Embedding modelinin eğitimi ve seçimi de bu noktada belirleyicidir. - Chunking Stratejisi
Belgelerin ne şekilde parçalara ayrıldığı (chunking) getirme kalitesini ve LLM’ye sağlanan bağlamı doğrudan etkiler. Parça boyutu, çakışma oranı ve içerik yapısı iyi planlanmalıdır. En iyi chunking stratejisi genellikle deneme-yanılma ile belirlenir ve veri yapısına göre değişebilir. - LLM’lerin Bağlam Uzunluğu Sınırlamaları
Geniş context window sunan LLM’ler bile belli bir sınır dahilinde çalışır. Getirilen metin çok uzunsa, özetleme, kritik bilgileri seçme veya yeniden sıralama stratejileriyle bu verilerin bağlama sığdırılması gerekebilir. Bu, özellikle büyük belge koleksiyonlarıyla çalışırken önemli hâle gelir. - Gecikme (Latency)
RAG mimarisinde, retrieval aşaması ilave işlem gerektirir. Bu da klasik LLM çağrısına göre daha fazla gecikme yaratabilir. Gerçek zamanlı uygulamalarda bu sorunun aşılması için hızlı embedding modelleri, indeksleme optimizasyonu, önbellekleme (caching) gibi teknikler kullanılmalıdır. - Maliyet
Embedding üretimi (özellikle ücretli API veya GPU kullanılıyorsa), vektör veritabanı barındırma, LLM çağrıları gibi maliyet kalemleri göz önüne alınmalıdır. Sistem mimarisi planlanırken bu maliyetlerin net bir şekilde modellenmesi ve bütçeye dahil edilmesi gerekir. - Değerlendirme Zorluğu
Bir RAG sisteminin başarımını ölçmek, klasik metin üretim sistemlerine göre daha karmaşıktır. Yalnızca akıcılık değil, aynı zamanda bilgi doğruluğu, getirilen belgelerle alaka düzeyi ve sadakat (üretilen içeriğin kaynakla çelişmemesi) de değerlendirilmelidir. RAGAS gibi çerçeveler veya özel oluşturulan değerlendirme hatları bu süreci standartlaştırmak ve otomatikleştirmek amacıyla geliştirilmiştir.
RAG ve LLM'lerin Geleceği

Retrieval-Augmented Generation (RAG), durağan bir kavram değildir. Akademik kurumlar, endüstri laboratuvarları ve öncü araştırmacılar bu alanı sürekli geliştirerek sınırlarını zorlamaktadır.
Gelişen RAG Teknikleri ve Yenilikler
Arxiv gibi platformlarda yayımlanan makaleler ve NeurIPS, ICML, ACL gibi önde gelen yapay zeka konferanslarında sunulan çalışmalar, RAG kapasitesini genişletmektedir. Öne çıkan bazı yenilikçi yönelimler şunlardır:
- Hibrit Getirme Yöntemleri: Anlamsal (dense vector) ve kelime tabanlı (lexical) aramaların birleştirilmesiyle hem anlam benzerliği hem de tam eşleşmelerin kapsandığı daha güçlü getirme süreçleri oluşturulmaktadır.
- Uyarlanabilir Getirme (Self-Correcting RAG): LLM veya bir aracı bileşen, getirilen ilk belgeleri değerlendirerek farklı veya daha fazla bilgi gerektiğine karar verip sorguyu yeniden düzenleyebilir. Bu yöntem, insan benzeri sorgulama süreçlerini yansıtır
- Konuşmaya Duyarlı RAG: Diyaloglarda çoklu adım bağlamı sürdürebilen, takip soruları ve zamirli ifadeleri anlayarak bilgi getiren RAG sistemleri geliştirilmektedir.
- Çok Aşamalı Getirme (Multi-Hop): Farklı belge ve veri noktaları arasında bağlantı kurarak daha karmaşık akıl yürütmeler gerektiren sorulara yanıt üretebilen sistemler geliştirilmekte.
- LLM Ajanlarıyla Entegrasyon: RAG, daha gelişmiş problem çözme sistemlerinde temel bir bileşen hâline gelmektedir. LLM, ne zaman ve nasıl veri getireceğine karar verebilecek şekilde yapılandırılmaktadır.
RAG’in Kurumsal ve Uzmanlaşmış Yapay zeka Uygulamalarındaki Rolü
RAG, Generative AI çözümlerinin güvenilir, uygulanabilir ve ölçeklenebilir hâle gelmesinde giderek daha kritik bir rol oynamaktadır. LLM’leri gerçek, güncel ve alan bazlı bilgiyle destekleme yeteneği sayesinde, ROI (yatırım geri dönüşü), doğruluk ve risk yönetiminin ön planda olduğu kurumsal kullanımlarda vazgeçilmez hâle gelmektedir.
Gelecekte RAG’in şu alanlarda daha fazla yaygınlaşması beklenmektedir:
- Genel amaçlı LLM’lerin alan bazlı bilgiyle özelleştirilmesi: Finans, hukuk, sağlık, mühendislik gibi alanlarda yeniden eğitim gerektirmeden yüksek doğruluklu çözümler sunulabilir.
- Yeni nesil kurumsal arama ve bilgi keşif sistemleri: Belge listesi yerine doğal dilde yanıtlar sunan akıllı arama platformlarının temelinde RAG yer alacaktır.
- Güvenilir yapay zeka asistanları ve yardımcı uygulamalar: Bağlama duyarlı, doğru bilgi getirme yeteneği olan LLM tabanlı yardımcılar yaygınlaşacaktır.
- Uyumluluk ve denetlenebilirlik gerektiren sektörlerde kullanım: Yapay zeka tarafından üretilen içeriklerin kaynakları izlenebilir hâle getirilerek yasal gereklilikler karşılanabilecektir.
Sonuç: RAG ile LLM Performansını Geleceğe Taşımak
Retrieval-Augmented Generation (RAG), Large Language Models (LLMs) için pratik ve gerçek dünya senaryolarında potansiyelini tam anlamıyla ortaya çıkaran kilit bir teknolojidir. LLM’lerin harici, güncel ve alan bazlı bilgiye erişmesini sağlayarak onları çok daha doğru, güncel, güvenilir ve faydalı hâle getirir.
Giderek artan kurumsal benimseme ve güçlü araştırmaların da gösterdiği gibi, RAG LLM sistemleri, LLM’lerin genel ve önceden eğitilmiş bilgi sınırlarını, gerçek dünyada ihtiyaç duyulan özgül ve zamanında bilgilerle tamamlar. Bu sayede geliştiriciler ve kurumlar, yalnızca prototip değil, üretime hazır, akıllı ve güvenilir yapay zeka çözümleri geliştirebilir.
Siz de yapay zeka tabanlı çözümlerinizi güçlendirmek için RAG stratejisini uygulamayı düşünebilir veya daha bilgili ve bağlama duyarlı sistemler inşa etmeye bugün başlayabilirsiniz. Gerçeklere dayalı ve kullanıcı bağlamını anlayan yapay zekaya giden yol, RAG sayesinde ciddi şekilde hızlanmaktadır.
The key takeaway, supported by growing adoption and extensive research, is that RAG LLM systems bridge the critical gap between the general, pre-trained knowledge of LLMs and the specific, timely information crucial for most real-world applications. This empowers developers and organizations to build more intelligent, trustworthy, and truly useful AI-powered solutions, moving beyond proof-of-concept to production-ready applications that deliver tangible value.
Explore how implementing a RAG strategy can enhance your AI-powered solutions or start building more knowledgeable and trustworthy AI applications with RAG today. The journey towards more factual and context-aware AI is significantly accelerated by this powerful approach.
RAG LLM Hakkında Sıkça Sorulan Sorular
RAG, LLM’lerin halüsinasyon üretme riskini azaltır, güncel ve alan spesifik bilgilere erişim sağlar, modelin yeniden eğitilmesine gerek kalmadan bilgi güncellemeleri yapılmasına olanak tanır ve yanıtların kaynaklarını belirtme imkanı sunar.
Fine-tuning, LLM’nin parametrelerini belirli bir veri setiyle yeniden eğitmeyi içerirken, RAG harici bilgi kaynaklarını kullanarak modelin yanıtlarını zenginleştirir. RAG, daha az maliyetli ve daha hızlı uygulanabilir bir çözümdür.
RAG sistemi kurmak için öncelikle bilgi tabanı oluşturulur, bu veriler embedding modelleriyle vektörlere dönüştürülür ve bir vektör veritabanına kaydedilir. Kullanıcı sorguları da vektörleştirilerek en alakalı bilgiler getirilir ve LLM’ye bağlam olarak sunulur.
RAG, müşteri destek sistemleri, arama motorları, içerik üretimi, sağlık, finans ve hukuk gibi alanlarda kullanılır. Özellikle güncel ve doğrulanabilir bilgi gerektiren uygulamalarda tercih edilir.
RAG sistemlerinde bilgi getirme kalitesi, chunking stratejileri, LLM’lerin bağlam uzunluğu sınırlamaları, gecikme süreleri ve maliyet gibi zorluklar bulunmaktadır. Bu sorunlar, uygun tekniklerle minimize edilebilir.
RAG, LLM’lerin yanıtlarını harici ve doğrulanabilir bilgi kaynaklarıyla destekleyerek, modelin sadece eğitim verilerine dayanarak uydurma bilgiler üretmesini engeller. Bu sayede daha güvenilir ve doğru yanıtlar elde edilir.
RAG sistemlerinde embedding modelleri (örneğin, BERT, Sentence-BERT), vektör veritabanları (örneğin, FAISS, Pinecone), bilgi getirme algoritmaları ve LLM’ler (örneğin, GPT-4, LLaMA) kullanılır.
RAG sistemlerinin değerlendirilmesinde, yanıtların doğruluğu, bağlam uygunluğu, bilgi getirme kalitesi ve kullanıcı memnuniyeti gibi kriterler göz önünde bulundurulur. Ayrıca, RAGAS gibi değerlendirme çerçeveleri kullanılabilir.
Gelecekte, RAG sistemlerinin daha gelişmiş bilgi getirme yöntemleri, adaptif öğrenme yetenekleri ve farklı alanlara özel uygulamalarıyla daha yaygın ve etkili hale gelmesi beklenmektedir. ( Kaynak: Vikipedi)